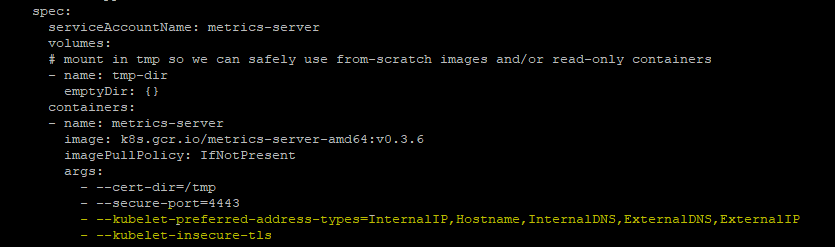
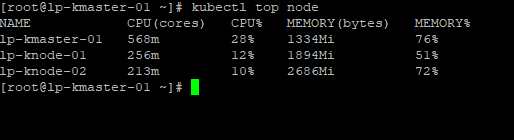
1.Deploy pushgateway to kubernetes
pushgateway.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pushgateway-deployment
labels:
app: pushgateway
env: prod
spec:
replicas: 1
selector:
matchLabels:
app: pushgateway
env: prod
template:
metadata:
labels:
app: pushgateway
env: prod
spec:
containers:
- name: pushgateway-container
image: prom/pushgateway
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "128Mi"
cpu: "200m"
limits:
memory: "256Mi"
cpu: "200m"
ports:
- containerPort: 9091
---
kind: Service
apiVersion: v1
metadata:
name: pushgateway-service
labels:
app: pushgateway
env: prod
spec:
selector:
app: pushgateway
env: prod
ports:
- name: pushgateway
protocol: TCP
port: 9091
targetPort: 9091
nodePort: 30191
type: NodePort2. Add pushgateway in /etc/prometheus/prometheus.yml
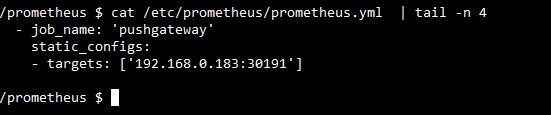
3. Push running docker status to pushgateway using below bash script and add it to crontab
job="docker_status"
running_docker=$(docker ps | wc -l)
docker_images=$(docker images | wc -l)
cat <<EOF | curl --data-binary @- http://192.168.0.183:30191/metrics/job/$job/instance/$(hostname)
# TYPE running_docker counter
running_docker $running_docker
docker_images $docker_images
EOF4. Data visualization in prometheus and pushgateway server
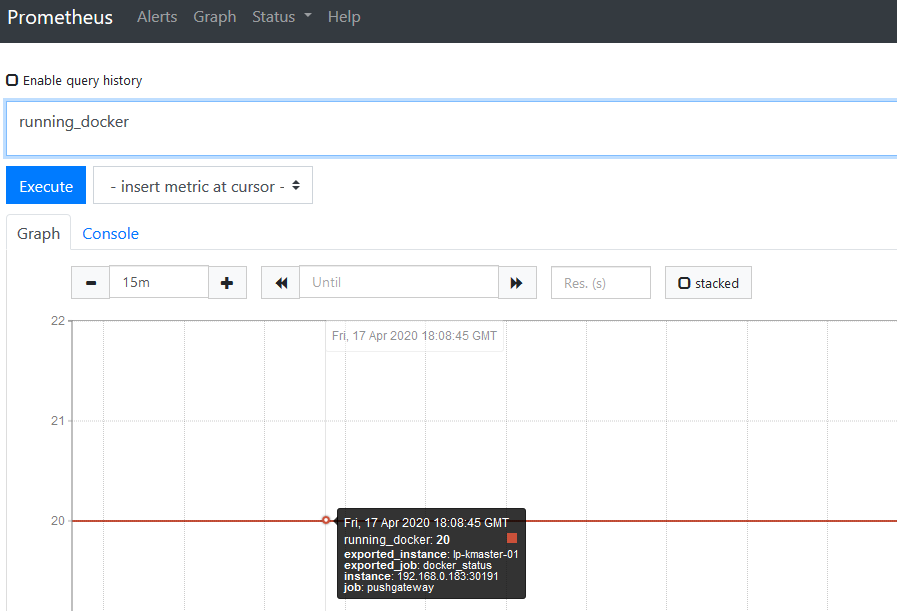
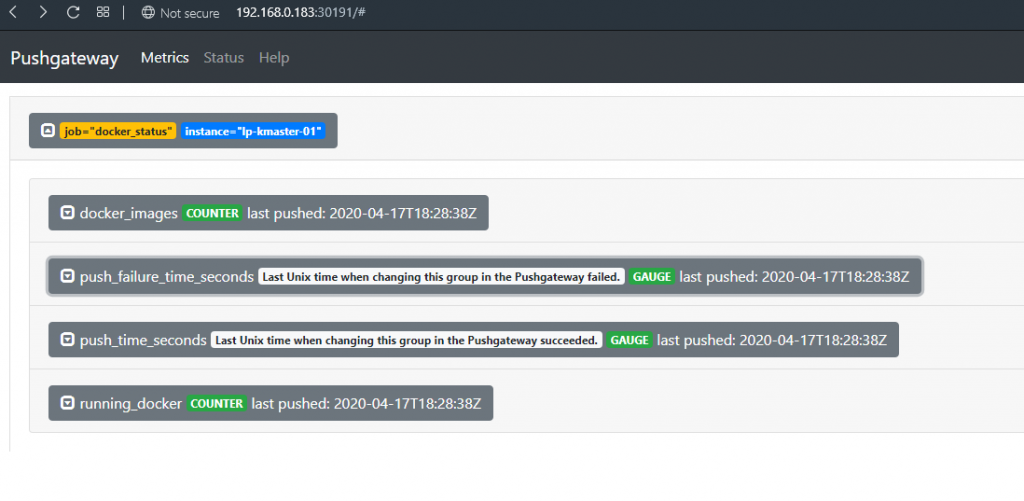
Python code:
job_name='cpuload'
instance_name='web1'
payload_key='cpu'
payload_value='10'
#print("{k} {v} \n".format(k=payload_key, v=payload_value))
#print('http://192.168.0.183:30191/metrics/job/{j}/instance/{i}'.format(j=job_name, i=instance_name))
response = requests.post('http://192.168.0.183:30191/metrics/job/{j}/instance/{i}'.format(j=job_name, i=instance_name), data="{k} {v}\n".format(k=payload_key, v=payload_value))
#print(response.text)pushgateway powershell command:
Invoke-WebRequest "http://192.168.0.183:30191/metrics/job/jenkins/instance/instace_name -Body "process 1`n" -Method Post$process1 = (tasklist /v | Select-String -AllMatches 'Jenkins' | findstr 'java' | %{ $_.Split('')[0]; }) | Out-String
if($process1 -like "java.exe*"){
write-host("This is if statement")
Invoke-WebRequest "http://192.168.0.183:30191/metrics/job/jenkins/instance/instace_name" -Body "jenkins_process 1`n" -Method Post
}else {
write-host("This is else statement")
Invoke-WebRequest "http://192.168.0.183:30191/metrics/job/jenkins/instance/instace_name" -Body "jenkins_process 0`n" -Method Post
}