1. Get the metrics server code form github
git clone https://github.com/kubernetes-sigs/metrics-server
cd metrics-server
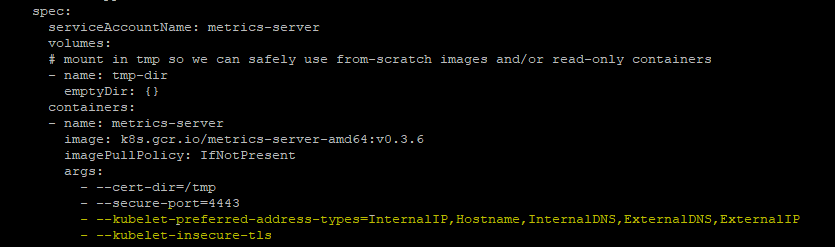
#Edit metrics-server-deployment.yaml
vi deploy/kubernetes/metrics-server-deployment.yaml
#And add below args
args:
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
- --kubelet-insecure-tlsmetrics-server-deployment.yaml will look like below
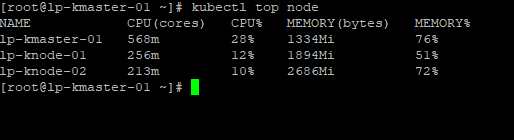
2. After deployment we will get the cpu and ram usage of node as below
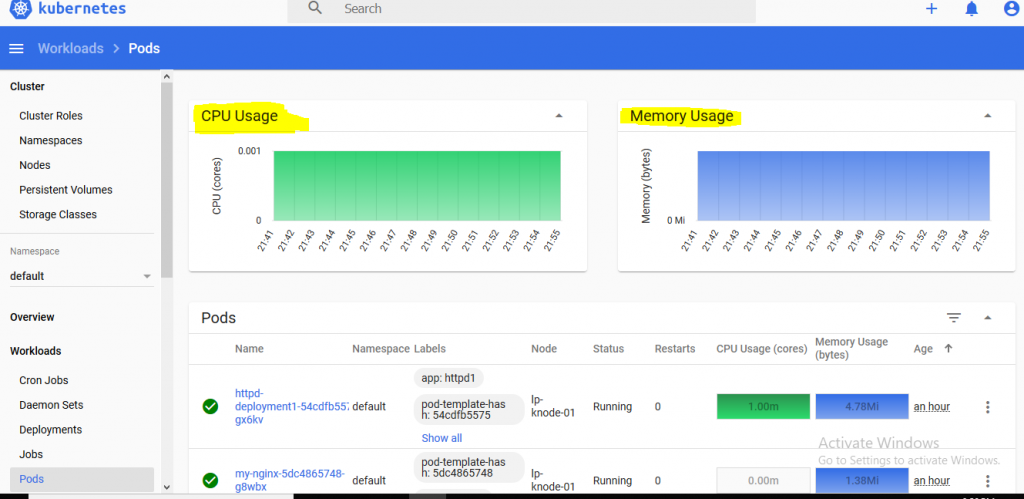
3.Now we can write Horizontal Pod Autoscaler as below that will auto scale nginx-app1 deplyment if cpu usage will get above 80% max 5 pods.
– It’s checks every 30 seconds for scaling the deployment
– It’s scale downs the deployment after 300 seconds if the load goes down
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v1
metadata:
name: nginx-app1-hpa
spec:
scaleTargetRef:
kind: Deployment
name: nginx-app1
apiVersion: apps/v1
minReplicas: 1
maxReplicas: 5
targetCPUUtilizationPercentage: 804. nginx-app1.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-app1
spec:
selector:
matchLabels:
run: nginx-app1
replicas: 2
template:
metadata:
labels:
run: nginx-app1
spec:
containers:
- name: nginx-app1
image: nginx
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "200m"
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: nginx-app1-svc
labels:
run: nginx-app1-svc
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30083
selector:
run: nginx-app1
type: NodePort5. Random load generator
while(true)
do
curl -s http://SERVICE_NAME
curl -s http://SERVICE_NAME
curl -s http://SERVICE_NAME
curl -s http://SERVICE_NAME
curl -s http://SERVICE_NAME
done