helm repo add kubecost https://kubecost.github.io/cost-analyzer/
helm upgrade --install kubecost kubecost/cost-analyzer prometheus.server.persistentVolume.enabled=false --namespace kubecost --create-namespace Tag: kubernetes
kubernetes 1.23 to 1.24 ,1.25, 1.26, 27, 28, 29 upgrade
- install containerd and remove docker
systemctl stop docker
dnf remove docker-ce -y
dnf install containerd -y
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
systemctl start containerd
systemctl enable containerd- edit /var/lib/kubelet/kubeadm-flags.env add below
KUBELET_KUBEADM_ARGS="--pod-infra-container-image=k8s.gcr.io/pause:3.5 --container-runtime=remote --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
OR
KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
- edit /etc/crictl.yaml to remove crictl warning message
echo 'runtime-endpoint: unix:///run/containerd/containerd.sock' > /etc/crictl.yamlsystemctl start containerd
#[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist
#[ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
lsmod | grep -i netfilter
modprobe br_netfilter
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 'net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1' > /etc/sysctl.d/k8s.confRemove CNI binary form /opt/cni/bin/*
rm -rf /opt/cni/bin/*For Ubuntu 22.04 need to install containernetworking-plugins:
failed to load CNI config list file /etc/cni/net.d/10-calico.conflist: error parsing configuration list: unexpected end of JSON input: invalid cni config: failed to load
apt install containernetworking-plugins
#crontab entry for ubuntu
@reboot modprobe br_netfilter
@reboot echo 1 > /proc/sys/net/ipv4/ip_forward
Note : weaves CNI had issue with containerd , k8 1.24 I uninstalled it.
It’s working with calico CNI
- For new containerd version above 1.5.9
vi /etc/containerd/config.toml
SystemdCgroup = true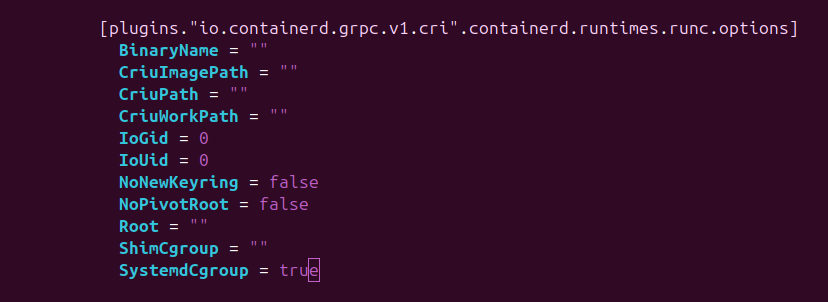
- For Raspberry pi edit
/boot/firmware/cmdline.txtand append this line
cgroup_enable=cpuset cgroup_enable=memory- Kernal 6.12.40-v8+ has some issues with cgroup_enable=memory need to switch to 6.6
root@lp-arm-2:~# cat /proc/cmdline
coherent_pool=1M 8250.nr_uarts=0 snd_bcm2835.enable_headphones=0 cgroup_disable=memory .....
grep memory /proc/cgroups
dmesg | grep 'Kernel command line'
strings /boot/kernel8.img | grep cgroup_disable
- Ubuntu 22.04 kubelet SandboxChanged issue fixed set SystemdCgroup = true in /etc/containerd/config.toml : https://github.com/kubernetes/kubernetes/issues/110177#issuecomment-1161647736
- https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/network-plugins/
- https://kubernetes.io/docs/tasks/administer-cluster/migrating-from-dockershim/troubleshooting-cni-plugin-related-errors/
- https://github.com/weaveworks/weave/issues/3942
- https://github.com/weaveworks/weave/issues/3936
- https://github.com/awslabs/amazon-eks-ami/blob/master/scripts/install-worker.sh
kuberntes upgrade useful command
kubectl drain ip-10-222-110-231.eu-west-1.compute.internal --delete-emptydir-data="true" --ignore-daemonsets="true" --timeout="15m" --force
kubectl get nodes --label-columns beta.kubernetes.io/instance-type --label-columns beta.kubernetes.io/capacity-type -l role=worker- deleted pod automatically
#send output to env_output.tail
for i in $(cat qa.node);
do echo "draining node : $i"
kubectl drain $i --delete-emptydir-data="true" --ignore-daemonsets="true" --timeout="15m" --force >> env_output.tail 2>&1
echo "completed node : $i"
done
#read env_output.tail to delete pod
while(true)
do
pods=$(tail -n 20 env_output.tail | grep "error when evicting" | cut -d '(' -f1 | awk -F 'evicting' '{print $2}' | uniq | awk '{print $1,$2,$3}')
echo pods: $pods
apod=$(echo "$pods" | sed 's/"//g')
echo apod: $apod
echo "kubectl delete $apod"
kubectl delete $apod
sleep 5
done#namespace=$(kubeclt get ns | tr "\n" " ")
namespace="abc xyz"
for ns in $namespace
do
deploy=$(kubectl get deploy -n $ns | grep -v '0/' | awk '{print $1}' | sed 1d)
for i in $deploy
do
kubectl -n $ns patch deployment $i -p '{"spec": {"template": {"spec": {"containers": [{"name": "'$i'","resources": { "requests": {"cpu": "100m"}}}]}}}}'
echo "patched : $i ns=$ns"
done
done
upgrade helm chart version
- Go to latest chart
cd /path/to/helmchart-vaules-file- Do dry run and verify changes
helm upgrade release_name . --debug --dry-run- Everything looks good upgrade the helm chart
helm upgrade release_name . --debugAccess/copy files in distroless container
Method 1 – using basic shell command
# Get the PID
ps -ef | grep <containerID>
# View all files
ls -ltr /proc/<PID>/root/Method 2 – using kubectl , docker cp command
docker cp containerID:/path/to/file /path/file
kubectl cp pod_name:/path/to/file /path/file
CKA certification tips
- Join the exam 20 min before it start as it will take time to verify all your ID and Place.
- During the exam you will have access to http://kubernetes.com/docs
- Every question shows % weight so you can take high % weight questions first if it’s not related to other question.
- Practice is very important. Complete mock testing at least 3-5 times
- Complete your training with KodeKloud with practice and mock test.
- You can practice your exam on killer.sh which you get it for free once you buy CKA certification. 2 mock sessions are available 36 hours each
- killer.sh questions are hard. I was able to complete around 20 in 2 hours.
- Exam time is 2 hours as of 25th JAN 2022
- There was 17 question(there can be more than 17 also)
- Exam result will be sent in 24 hours.(Exactly 24 hours 1 minute)
Custom Daemonset command based on host_ip in kubernetes
Why?
– When we need to add some extra functionally to daemonset based on which worker node it’s running on
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: custom-daemonset
name: custom-daemonset
spec:
selector:
matchLabels:
app: custom-daemonset
template:
metadata:
labels:
app: custom-daemonset
spec:
containers:
- command:
- /bin/bash
- -c
- |
echo "$STARTUP_SCRIPT" > /tmp/STARTUP_SCRIPT.sh
/bin/bash /tmp/STARTUP_SCRIPT.sh
env:
- name: HOST_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: STARTUP_SCRIPT
value: |
#!/bin/bash
if [ $HOST_IP == "192.168.0.184" ]; then
echo "HOST_IP is $HOST_IP"
else
echo "HOST_IP does not match $HOST_IP"
fi
sleep 600
image: nginx
imagePullPolicy: IfNotPresent
name: custom-daemonsetRef : https://github.com/kubernetes/kubernetes/issues/24657#issuecomment-577747926
Simple Kubernetes NFS Subdir – External Provisioner
Why?
– No need to create directory manually on nfs server
– Easy
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
helm upgrade --install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --set nfs.server=192.168.0.182 --set nfs.path=/mnt/nfs2 --set storageClass.defaultClass=true --set storageClass.onDelete=retain
deployment-nginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 1
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: pvc-claim
mountPath: /data
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "100m"
volumes:
- name: pvc-claim
persistentVolumeClaim:
claimName: test-claim
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
annotations:
nfs.io/storage-path: "test-path"
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10MiMore : https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
how to start learn docker and kubernetes
- Linux – installation of different distro with lvm, encrypted lvm, plain
- Shell scripting – auto restart job , sed , awk
- Docker – jenkins setup, wordpress setup with persistent volume
- kubernetes – cluster setup, deployment
renew kubeapi server certs in kubernetes
kubeadm certs check-expiration
kubeadm certs renew allerror : x509: certificate has expired or is not yet valid
Note : move /etc/kubenetes/admin.conf to /root/.kube/config and restart control node and worker node to update cert
https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-certs/